| |
|
|
| Bible Code Digest: May/June 2026 Continued |
|
|---|
Non-Random Equidistant Letter
Sequence Extensions in the Hebrew Bible
By Richard E. Sherman, FCAS, MAAA, and Nathan Jacobi, Ph.D.
Summary
Bible codes are equidistant letter sequences (ELSs) that appear in the Hebrew Bible.
Extended Bible codes are found by first locating a single word ELS with a given skip and then by searching for extensions in good Hebrew on both sides, continuing at the same skip. The longer an extended ELS is, the more improbable it is. A Markov chain model was developed for estimating the probability of chance occurrence of extended ELSs of a variety of different lengths. Monte Carlo simulations of the extension discovery process were also used to determine the probability of different outcomes, by chance, around the expected outcome.
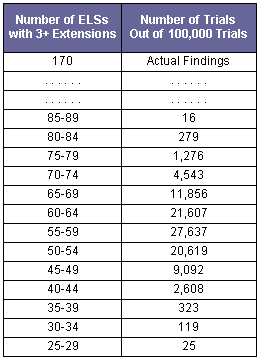
Over the past 4� years, 1,064 search terms were examined to determine if extensions in good Hebrew existed around them. For 55.2% of the initial search terms, no extension was found. This indicated an extension discovery rate of 25.6%. Based on the Markov chain model, this discovery rate implies that 57.69 extended ELSs should consist of three or more extensions. In actuality, 170 such extended ELSs were discovered. Using computer simulation with 100,000 trials, the number of extended ELSs with three or more extensions varied from 28 to 88, as illustrated in Graph 1 below.
Graph 1
Comparison of Number of Extended ELSs with Three or More Extensions
Expected by Chance (Left Histogram) and Actual Number Found (Far Right)
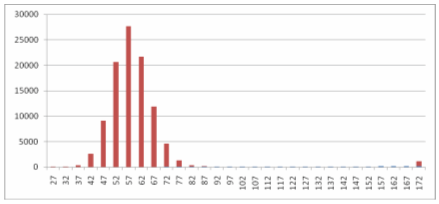
The vertical axis displays the number of trials, out of 100,000, where the given number of findings occurred. For example, the largest number of trials (27,637) coincides with 57 extended ELSs found. The number "57" represents all trials where there were 55 to 59 extended ELSs with three or more extensions. Similarly, the number "172" on the far right represents the actual result of 170 findings, as 172 is the middle number in the range of 170 to 174 findings. That the actual result is radically greater than the entire range of what is possible by chance means that the null hypothesis should be rejected.
Table 1 summarizes the results shown in Graph 1 and also displays comparable results for different numbers of extensions. In every case other than the number of extended ELSs with two extensions, the null hypothesis that the actual finding can be attributed to chance should be decisively rejected.
Table 1
Comparison of Expected and Actual Number of Findings
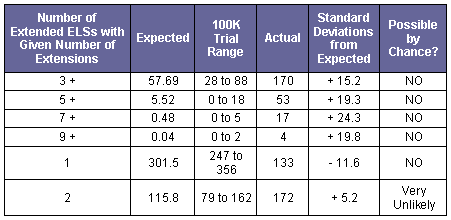
If the statistical significance standard is at the 0.001 level, or 1 in 1,000, then a result that is 3.09 or more standard deviations out should result in rejection of the null hypothesis. Chance should be rejected as a reasonable explanation. If the standard is at the 1 in 1 million level, then a result that is 4.75 or more standard deviations out should result in rejection of the null hypothesis. At the 1 in 1 billion level, 6.00 standard deviations is the boundary value. At the 1 in 1 trillion level, 7.34 standard deviations is the boundary value.
Introduction
Bible codes are equidistant letter sequences (ELSs) that appear in the Hebrew Bible. ELSs can appear in any language in any text. For example, within the English word "generalization," "nazi" is an ELS that appears when every third letter is selected (g e n e r a l i z a t i o n). The skip of this ELS is +3. An ELS can have a negative skip. "Love" is an ELS with a skip of -1 within the word "r e v o l v e."
The more letters in a given ELS, the less likely it is a chance occurrence.
An extended ELS is found by first locating a short search term as an ELS, such as "love"within a text, and then checking to see if this "encoded" word is part of a longer "code." This is done by first extracting a letter string with the same skip as the initial ELS and that surrounds and includes the initial ELS. This letter string is examined for the presence of additional phrases or sentences that are a continuation of the initial ELS. As an example, from the sentence, "The world seems to revolve around her," the following search string around the "love" ELS was extracted by reviewing the letters of the sentence in reverse order:

The two words, "rots me" form a phrase that extends the initial "love" ELS in good English. One other word ("row") appears in this search string, near the end. However, it is separated from other "hidden" words by gibberish. In searching for extensions, all the words must appear one right after the other. No nonsense letters between words are allowed.
Consider a specific example of an extended ELS. The original search term was New York. It was found as an ELS with a skip of +15. The extended ELS was The lenders will strike the poor in her. New York, my broker is afraid. The following table displays the two extensions found around the original search term.

These extensions were found in the one and only string of letters derived by starting with the New York ELS with a skip of +15 and extracting every fifteenth letter from the Hebrew Bible in the passage where the New York ELS was found. There were only two opportunities to find an extension next to the original search term. After an extension was found right before the New York ELS, this created another opportunity to find yet another extension right before it. So there were only a couple of opportunities to find something intelligible in good Hebrew when examining a letter string for an extended ELS.
The Investigation
During the period from July 2026 to April 2026, a Hebrew expert (Nathan Jacobi, Ph.D.), examined 1,064 ELSs for the presence of extensions in good Hebrew, either immediately before or after the given ELS. The initial search terms were selected on the basis of likely relevance to current events (Appendix C). No initial ELSs were removed from the list for any reason, so the 1,064 ELSs represent a complete collection of all initial ELSs that were searched for potential extensions. Two types of searches were performed. In the first type, for each search term, ELSs with the ten shortest skips in the Hebrew Bible were examined for possible extensions. In the second type, ELSs with the ten shortest skips where at least one letter of the ELS appeared in a selected passage were examined. In each case, the passage was selected on the basis of the relevance of the literal text to the topic under investigation. The beginning and ending of the selected text were not modified to "optimize" the number of extended ELSs found.
For 55.357% of these initial ELSs, no extension was found on either side. This translates into a discovery rate of 25.6%. Suppose d is the probability of discovering an extension around an existing ELS, either before or after it. For no extension to be found on either side, no extension must appear twice (both before and after the initial ELS). So (1.0 - d)2 = 55.357%, (1.0 � d) = 74.402% and d = 25.6%. And we have the formula,
(1) d = 1.0 � (square root of the %-age of searches where no extension was found).
If an extension is found, one new opportunity to find yet another extension is created. That opportunity will consist of the new letters that are now next to the extension that had just been discovered. There is no new opportunity on the other side of the ELS where an extension wasn't found, since that opportunity has already been counted.
In Appendix A, a Markov chain model was used to derive the formula for the total number of final ELSs consisting of k extensions expected to be found by searching around n initial ELSs, given a discovery rate of d:
(2) n ( k + 1 ) dk ( 1 � d )2.
Formula (2) was used to determine the expected number of lengthy ELSs displayed in Table 2 for several length categories from the examination of 1,066 initial ELSs.
Table 2
Comparison of Actual with Expected Number of Extended
ELSs by Length Category (Assuming a 25.6% Discovery Rate)
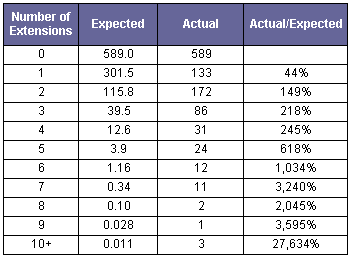
The presence of very short extensions was surprisingly rare, compared to expectations assuming randomness (133 actual versus 301.5 expected). Correspondingly, for the remaining extended ELSs, the presence of lengthy extensions far exceeded what would be expected by chance. In other words, there was a clear tendency for there to not be any extension around the original term, or for the extension(s) to be noticeably longer than expected by chance. The number of actual and expected ELSs with no extensions was identical because the discovery rate was derived from the exact number of ELSs where no extension was found.
If we combine the results in the above table for three or more extensions, we see that although 57.7 ELSs were expected by chance, 170 were actually discovered. The greatest number of ELSs with three or more extensions produced from 100,000 trials of the Markov chain model simulation was 88. It is evident that the null hypothesis that the lengthy extension findings are due to chance should be rejected.
Corresponding results for compilations for each given number of extensions, or more than the given number, are as follows:
Table 3
Comparison of Actual with Expected Number of Extended ELSs by
Given Length (or Longer) Category (Assuming a 25.7% Discovery Rate)
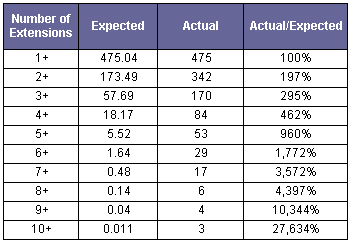
The consistent, dramatic excesses of the actual number of extended ELSs for each category of number of extensions are conclusive evidence that the Hebrew Bible was intentionally encoded with extended ELSs.
Tables 2 and 3 also indicate that the terseness of Hebrew and the absence of vowels can result in the "discovery" of some longer extended ELSs, simply due to chance.
Appendices B and D provide a listing of all ELSs for which extensions were found. These extended ELSs are presented in descending order of length, first in terms of the number of actual extensions found, and second in descending order of the total number of letters in the extension(s).
Two Very Different Types of Bible Code Findings
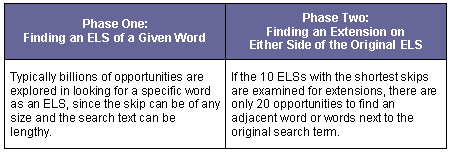
The process of finding ELS extensions consists of two radically different phases.

Critics of Bible codes point out that ELSs can be found in any text. And they are right�because there are billions of opportunities to find what you are looking for. However, these same critics are silent about the fact that this argument has no validity regarding Phase Two. In that phase, there are only two opportunities to find something: immediately prior to and immediately subsequent to the original search term. Typically, such critics simply ignore any claims about the discovery of extended codes. If they do mention any extended codes, they dismiss them by alleging that the quality of the Hebrew is poor, even though they offer no reason for anyone to respect their implied mastery of Hebrew.
How can we say there are billions of opportunities to find something in Phase One? The Hebrew Bible is 1,196,921 letters long. For simplicity suppose our search text is 1,000,000 letters long. Suppose the skip can be any size from 1 to 10,000, and can be positive or negative. For each starting letter, there are 10,000 opportunities to find a given ELS, going in a forward direction, and another 10,000 opportunities going in a backward direction. So we have 1,000,000 x 10,000 x 2, or 20,000,000,000 opportunities to find the given ELS.
In doing searches, additional copies of the entire search text are appended, one before and one after the original search text.

The first letter of any ELS we search for must appear in the original search text. However, some of the other letters of the ELS could appear in the preceding or subsequent copy of the search text.
So Phases One and Two are radically different, and should be treated as such when assessing the probability of chance occurrence of ELS phenomena.
Background
The history of Bible code research can be divided into two parts: (1) Investigations based on Phase One searches, and (2) Investigations based on combined Phase One and Phase Two searches.
Phase One Searches
In 1994 the paper, "Equidistant Letter Sequences in the Book of Genesis," was published in the journal Statistical Science. In it three Israeli mathematicians, Dr. Eliyahu Rips of the Hebrew University of Jerusalem, Dr. Doron Witztum and Yoav Rosenberg of the Jerusalem College of Technology, described the results of an experiment in which the proximity of such sequences (ELSs) for related topics tended to be in closer proximity in the Book of Genesis than in randomized reorderings of that text. The ELSs studied were the names of 66 of the most famous rabbis in Jewish history and their dates of death or birth. Numerous mathematicians have claimed that the Witztum Rosenberg Rips paper was flawed, while others have staunchly defended it.
In 1997 Michael Drosnin authored the book, The Bible Code, which topped the New York Times bestseller list for many weeks. An atheistic Jew, Drosnin claimed that the Bible was filled with ELS codes about numerous current events and that this was proof that some super-human intelligence who knew the future, had written the Old Testament.
Drosnin's book was repudiated by Dr. Rips, and dozens of mathematicians, since it presents dozens of trivial examples that are so simple that comparable examples could be extracted from any Hebrew book or random sequence of Hebrew letters.
Twelve years ago, Sherman began examining this phenomenon, strongly suspecting that there was nothing to it. After developing formulae to estimate the probability of chance occurrence of different purported Bible code phenomena, he concluded that virtually no examples from published books (at the time) were truly improbable.
Phase Two Searches
A few published examples were borderline in terms of improbability, so the help of a Hebrew expert, Nathan Jacobi, Ph.D., was sought to enable the search for more extensive ELSs in the same vicinity as the published examples of Hitler codes from Genesis 8 (from Drosnin) and Jesus codes from Isaiah 53 (from Christian author Grant Jeffrey). Jacobi discovered numerous lengthy ELSs in the Isaiah 53 cluster. Sherman was forced to reverse his negative position on Bible codes, which he had been presenting on a website, and he changed the name of the site to biblecodedigest.com.
To directly address the question of the purported validity of Bible codes, an impartial comparison of a collection of Bible codes with a parallel set of codes from an admittedly ordinary book was made. A scientific paper presenting the results of the Islamic Nations ELS extension experiment was posted at http://biblecodedigest.com/page.html/186. Jacobi was given 100 predefined initial ELSs, equally drawn from the Hebrew text of Ezekiel and from a Hebrew translation of Tolstoy's War and Peace. He searched for extended ELSs around each initial ELS�absent any knowledge of the source of each letter string. The two collections of extended ELSs were then compared and analyzed. It was concluded that the differences were statistically significant, but not entirely conclusive. Also included was a review of extended ELSs discovered in Ezekiel 37. The actual number of extended ELSs with 3+ extensions (33) was far outside the range indicated by a simulation of 1 million trials (0 to 18), indicating that these findings could not be due to chance.
Key Findings
Key findings from our research and analysis are:
- The null hypothesis that the actual number of long ELSs discovered is due to chance must be rejected. The frequency of long extended ELSs far exceeds that explainable by chance, clearly supporting the claim that some real Bible codes do exist. The chi square p-value indicated from Table 2 is 1.373 E -277 for codes with zero to ten extensions.
- Longer ELSs can be "discovered," even in ordinary texts, with a fair degree of frequency. This affirms the claim of code skeptics that "ELS codes" can be found in any book.
- The extension model provides a definitive benchmark for testing purported claims of the discovery of real Bible codes. It provides the expected number of extended ELSs that will consist of any given number of extensions. The mere discovery of a few lengthy extended ELSs does not provide credible evidence of the potential reality of Bible codes.
- If one multiplies the actual number of initial ELSs investigated (1,064) by the ratio of actual to expected ELSs in one of the longer categories, estimates can be obtained of the expected number of initial ELSs to have been investigated from the Hebrew Bible to find as many long ELSs as were actually discovered. For example, that expected number of extended ELSs with 7 or more extensions was 0.48, as compared with the 17 extended ELSs that were discovered. Multiplying the actual number of initial ELSs investigated (1,064) by (17/0.48=35.42) from Table 3 yields 37,686.9. This means that on average, one would need to examine 37,687 search terms for possible extensions to find 17 extended ELSs with seven or more extensions, if the searches were performed in a non-encoded text.
- Chances are significant that some of the shorter extended ELSs could be due to chance. For that reason, and many others cited in Appendix H, the content of extended ELSs should not be viewed as a reliable basis for making any predictions or for supporting any political or religious views that might be expressed in such extended ELSs.
- One hundred thousand trials were run of a simulation of the total number of ELSs with three or more extensions, given 1,064 initial ELSs and a discovery rate of 25.6%. The number of trials with various numbers of ELSs with 3+ extensions is shown in Table 4. The exceptionally large gap between the simulated results (which range between 28 and 88) and the actual number of 170 ELSs illustrates how infinitesimal is the probability of chance occurrence of findings as extensive as those described in this paper.
Table 4
Number of Trials with Given Numbers of ELSs with 3+ Extensions
- While the results of this analysis are sensitive to key assumptions such as the discovery rate from a non-encoded text (discussed in Appendix G), the gap between the results expected by chance from a non-encoded text and the actual findings is so great that it would not be bridged by any reasonable variations in these key assumptions and procedures. Furthermore, we have tried to give the benefit of the doubt on the side of underestimating the number of extensions present in many extended ELSs, as described in Appendix E.
- Even though the probability of chance occurrence of a collection of extended ELSs as extensive as those presented in this paper is extremely remote, there are compelling reasons to believe that the chance presence of this collection of extended ELSs is a virtual impossibility. The discovery rate of 25.6% underlying our calculations is that for finding an extension in good Hebrew. However, a high percentage of the extended ELSs consist of either relevant or plausible content. The proportion of these extended ELSs that are mysterious is relatively low, and the proportion of nonsense content is very small. While categorization of extended ELSs according to the quality of their content is inherently a subjective exercise, the reader is invited to examine the English translations of the extended ELSs disclosed in Appendices B and D to form their own opinion on this matter. Further, for each extended ELS, a page number on the biblecodedigest.com website is provided. These articles elaborate on the possible relevance and plausibility of the content of each of these extended ELSs. For example, on page 606 of the website, an extensive article details how the content of the seven sentences of the 108-letter-long Buddhist code make sense to Buddhists. And we also see that 108 is one of the most significant numbers in Buddhism and Hinduism. It is often additional observations such as these that make it clear that chance is not a rational explanation for the presence of so many plausible extended ELSs.
- The above considerations make the findings of this analysis conclusive in rejecting the null hypothesis that the number and length of the extended ELSs found is attributable to chance.
Additional Findings
In this section we present additional findings parallel to those disclosed above for the numbers of trials with given numbers of ELSs with 3+ extensions. Similar findings for ELSs with 5+ extensions are shown in Table 5 below. Again, there is a very large gap between the simulated results and the actual number of 53 ELSs with five or more extensions.
Table 5
Number of Trials with Given Numbers of ELSs with 5+ Extensions
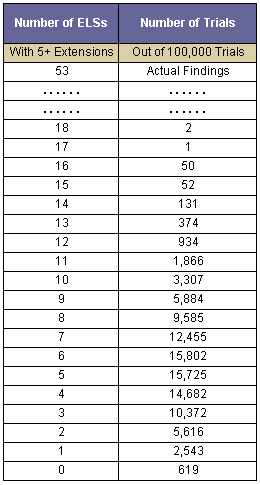
Again, there is an exceptionally large gap between the simulated results and the actual number of 53 ELSs with five or more extensions.
The number of trials with various numbers of ELSs with 7+ extensions is shown in Table 6 below. Again, there is a very large gap between the simulated results and the actual number of 53 ELSs with five or more extensions.
Table 6
Number of Trials with Given Numbers of ELSs with 7+ Extensions
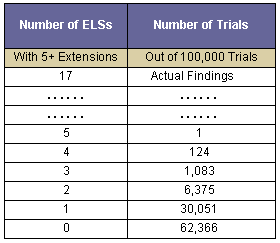
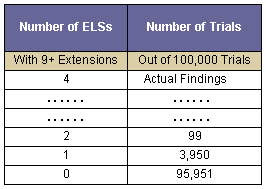
The number of trials with various numbers of ELSs with 9+ extensions is shown in Table 7 below. Again, there is a very large gap between the simulated results and the actual number of 53 ELSs with five or more extensions.
Table 7
Number of Trials with Given Numbers of ELSs with 9+ Extensions
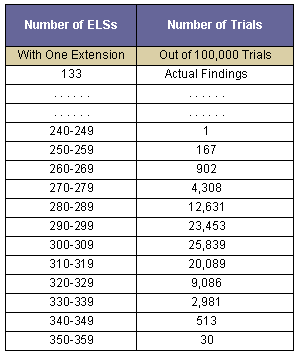
The number of trials with various numbers of ELSs with one extension is shown in Table 8 below. Again, there is a very large gap between the simulated results and the actual number of 133 ELSs with one extension.
Table 8
Number of Trials with Given Numbers of ELSs with One Extension
Appendices
In the eight appendices to this paper, the following topics are covered:
- A Markov Chain ELS Extension Model
- Comparison of the Number of Lengthy ELSs Found with Those Expected by Chance�For Extended ELSs with Three or More Extensions
- Summary of Searches for Extensions
- ELSs with One or Two Extensions
- Determining the Number of Extensions
- Independence of the Discovery Rate to the Number of Extensions Previously Discovered
- Dependence of the Conclusions on Variations in the Discovery Rate
- Commentary on the Content of Extended ELSs
The first four appendices focus on disclosing many of the most important details of the research completed. The last four appendices cover a range of topics related to the issue of "wiggle room," or the extent to which the findings of this paper could be affected by various choices made by the researchers in the course of this investigation.
About the Researchers
Richard E. Sherman is a Fellow of the Casualty Actuarial Society and a Member of the American Academy of Actuaries. He received a B.A. and M.A. in Mathematics from the University of California at San Diego, and passed three Ph.D. qualifying exams. He has 37 years of experience as a consulting actuary in serving numerous Fortune 500 corporations, major public entities, law firms and insurance companies in applying probability, statistics and econometric forecasting to risk management problems. He was a Principal with PricewaterhouseCoopers, the world's largest accounting and consulting firm, for seven years. He has authored five professional papers in actuarial journals and over 70 articles in trade publications. He directs the biblecodedigest.com website.
Nathan Jacobi, Ph.D., was educated in Israel from age six through his receipt of a doctorate (1945-1969), gaining a very thorough knowledge of both Biblical and contemporary Hebrew. In graduate school, he served as an interpreter (from English to Hebrew) of courses taught at the Weizman Institute of Science. He lectured at the Tel-Aviv University in Hebrew. He has over 20 years of experience in research, development and scientific computing in applied physics, aerospace and geophysics. He has taught numerous classes on Hebrew in recent years (1998-2003 and 2026 to present). In 2026, after living in the United States for many years, Nathan and his wife have moved back to Israel to be near their two children. In 2026, BCD conducted a two-part interview with Jacobi to discuss his life and his background in Hebrew.
Contact Information
Richard E. ("Ed") Sherman, FCAS, MAAA
President, Richard E. Sherman & Associates, Inc.
1257 Siskiyou Blvd. (183)
Ashland, OR 97520
(541) 821-4238 (cell)
(541) 488-7759 (fax)
E-Mail
Nathan Jacobi, Ph.D.
Kochav Hashahar 202
D.N. East Benjamin 90641
Israel
(212) 202-3247 (from USA)
011-972-2-940-9695
E-mail
Continue to Appendix A
|
|


 
Bombshell examines two massive, recently discovered clusters of codes in the Hebrew Old Testament. To read more about Bombshell, click here, or click below to order from Amazon today!

|

